pub-sub (Publish-Subscribe) system and
becoming a ubiquitous messaging system. Apache Kafka has become the de-facto standard for high performance
distributed data streaming as due to availability of large and growing developer community.
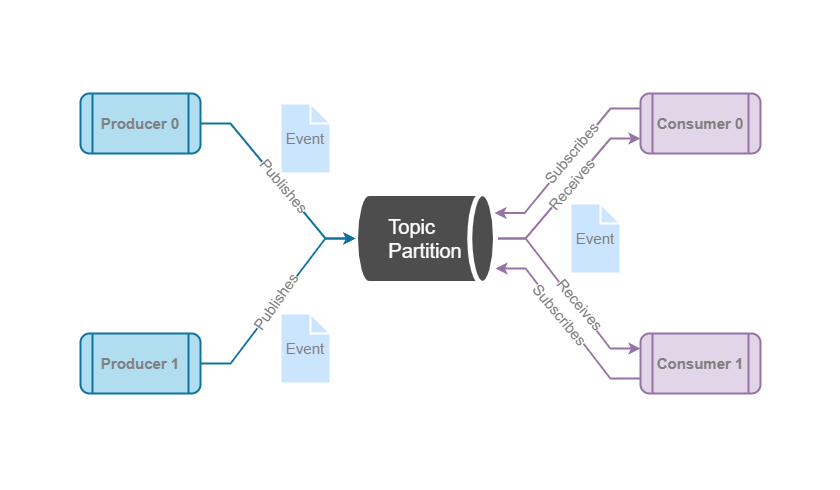
Let’s understand Kafka terminologies before we discuss about the use-cases and gotchas.
Event
Data Model
Typical events (records or messages) are combination of a Key, a Value, a timestamp and a list of headers. Keys can be a simple object or a complex object; these are not unique values, only used for the record ordering.Neverhard-codethe message key value.
Topic
Apache Kafka topics are not queues, these are actually append-only logs.
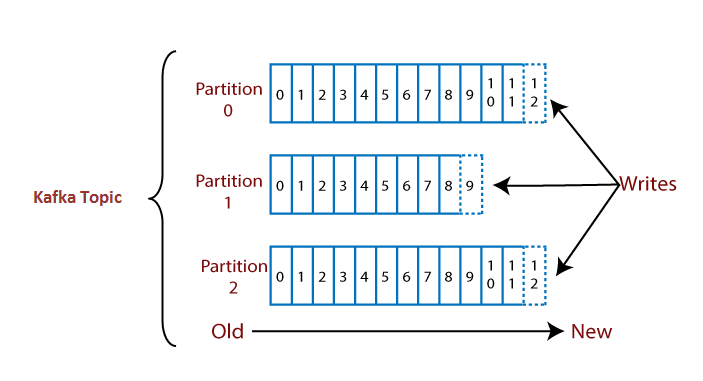
Durability
You can keep these logs as long as you would like to, from a second to multiple years. Apache Kafka allows us to expire these logs after specified time (time-to-leave) or a specified size. Typical use-case is time-to-leave (TTL).Partition
Storage
Partitioning takes a single topic logs and break them into multiple logs and store them into multiple partitions. Records without key are placed out randomly where are records with key are always placed in the same partition that allows to have guaranteed ordering. Storage of partitions across nodes allows us to store theoretically unlimited number of records.Optimal Partitions
With more partitions, you can handle a larger throughput since all consumers can work in parallel.- The load on the CPU will also get higher with more partitions since Kafka needs to keep track of all of the partitions.
- More than 50 partitions for a topic are rarely recommended good practice.
- Each partition in Kafka is single threaded, too many partitions will not reach its full potential if you have a low number of cores on the server. Therefore, you need to try to keep a good balance between cores and consumers.
Replication
Leader / Follower
Every partition has one leader and N-1 follower to provide fault-tolerance. In general, all read/write operation happens on the leader node, in case leader is down or unreachable one of the followers becomes a leader for that partition.Broker
A computer instance or a container running Apache Kafka process to manage partitions, replication of these partitions. In general broker stores some partitions of a topic. You should always keep an eye on partition distribution and do re-assignments to new brokers if needed, to ensure no broker is overloaded while another is idling.
Responsibilities
- Handles all Read / write request for a specific partition; for which, this broker is a leader.
- Manages replication of a partitions across brokers by communication
- Records for a topic can be stored across brokers
- All brokers in a cluster are act as both leaders and a follower.
Producer
Client application responsible for appending records to a Topic Partition. Because of a log structured nature of Kafka, and ability to share topics across multiple consumer ecosystems, only producers (or Kafka it-self in case of replication) are allowed to modify the data in the underlying log file. The actualI/O is performed by the broker nodes on behalf of the
producer client. Any number of producers may publish to the same topic, selecting the partitions used to persist
the records. Producer uses record key to identify a partition for a record.
Consumer
Offset
Each record with-in a partition is assigned an offset, a monotonically increasing number that serves as a unique identifier for a record in a partition. A consumer internally maintains an offset that points to the next record in a topic partition, advancing the offset for every successive read.
Applicable values are:None
You would rather set the initial offset yourself and you are willing to handle out of range errors manually.Earliest
When the consumer application is initialized the first time or binds to a topic and wants to consume the historical records present in a topic.Latest
This is default offset reset value, if you have not configured any, when are consumer application is initialized the first time and the consumer application starts with latest as offset reset, the consumer application receives the records that arrived to the topic after it subscribed to a topic or from last committed offset when consumer rejoins the cluster.Lag
A consumer is lagging when its unable to read from a partition as fast as messages are produced to it. Lag for a topic partition is expressed as number of offsets that are behind the head of partition.Recovery Time
The time required to recover from Lag (to catch up) depends on how soon the consumer is able to consume messages per second.Commit
The act of consuming a record does not remove it from topic partition, consumers have absolutely no impact on the topic and its partitions; A topic partition is an append-only ledger that may only be mutated by the Producer or Kafka itself. Consumer should commit its offsets frequently, so that if a consumer takes over the other topic partition due to re-balancing; it will start consumption from last committed offset.Consumer Group
Consumers can be organized into logical Consumer Group. Topic partitions are assigned to balance the assignments among all consumers in the group. All consumers work in a balanced mode; in other words, each record will be seen by only one consumer in a group.Re-balance
If a consumer goes away, the partition is assigned to another consumer in the group, this is referred as a re-balance. If a consumer joins, re-assignment of partitions is triggered, this is also referred as a re-balance.Idle Consumer
If there are more consumers in a group then partitions, some consumers will be idle. If there are fewer consumers in the group, some of them will consume from multiple partitions. The optimal number of consumers should be equal or less then number of partitions to avoid any idle consumer. Idle consumers will be leveraged when a consumer crash / removed.Isolated Consumer
A Topic Partition may read at a different cadence by any number of consumer groups. Consumers across groups are isolated and has their individual partition assignments and offsets.Who Uses Kafka?
According to stackshare there are1118
companies that use Kafka. Among them Activision,
Netflix,
Pinterest,
Tinder, Uber,
and of course Linkendin.
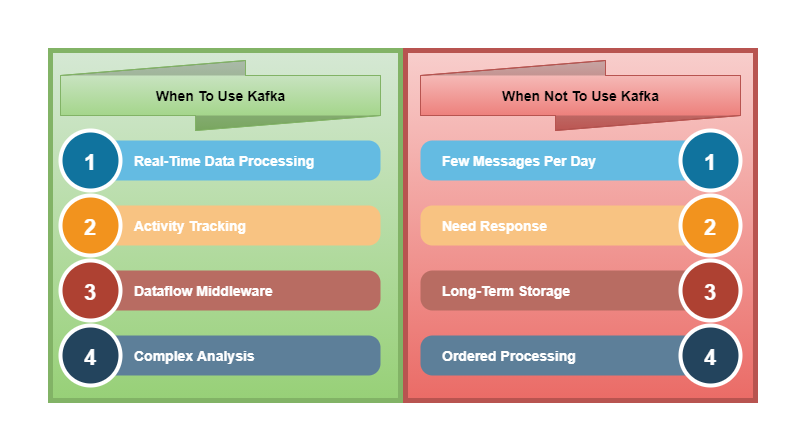
When To Use Kafka
There are many use cases of Apache Kafka, but we will discuss few most common and strong use cases.
Real-Time Data Processing
Most of the modern applications requires data to be processed as soon as it is available. This requires a data processing solutions that are efficient, resilient and scale easily.
One of the best use-case is IoT devices, they are often useless without real-time data processing ability. Apache Kafka can be best fit, since it is able to transmit large amount of data from producers to data handlers and then to data storages.
Activity Tracking
Kafka was originally developed for activity tracking to be used in LinkedIn. That implies each activity is published to central topics with one topic per activity type. Here, activity refers to page views, searches, user clicks, registrations, likes, time spent on certain pages by users, orders, etc.Dataflow Middleware
Kafka allows multiple applications to receive the same data at the same time. Using Kafka in the middle makes pipeline more open and pluggable.Complex Analysis
Kafka allows introspection of the most recent message or recent set of messages. Which allows us to detect outliers or anomalies but running complex analysis on the events.
A framework such as Apache Spark Streaming reads data from a topic, processes it and writes processed data to a new topic where it becomes available for users and applications. Kafka’s strong durability is also very useful in the context of stream processing.
When Not To Use Kafka
There are use cases where of Apache Kafka can be a overkill and we should not use, few of them are
Few Messages Per Day
Kafka is designed to cope with the high load. We should make use of traditional message queues like RabbitMQ to process small amount ofup to several thousandmessages per day as Kafka can be an overkill.
Need Response
Being apub-sub (Publish-Subscribe) system Kafka does not offer an ability to provide
acknowledgement back to producer on message consumption by a consumer.
Long-Term Storage
Well Kafka supports saving data during a specified retention period, but my recommendation is not to have this for too long as Kafka needs additional resources to manage large amount of data. We should make use of database like Cassandra, or MongoDB for long term data storage instead of using Kafka. Databases have versatile query languages and support efficient data inserting and retrieving.Ordered Processing
Ordered processing of all the messages requires a single consumer and single partition as Kafka does not support message ordering across partitions. But this is not at all the way Kafka works and we do have multiple consumers and multiple partitionsby design one consumer consumes from one partitionand because of this, it won't serve the use case that we are looking to implement.
Gotchas
Apache Kafka Shortcoming that usually causes developer frustrations in the production environments due to unexpected behaviors.Think before using out of the box configuration as is.
Tunable Knobs
The number of configuration parameters in Kafka can be overwhelming, not only for new commers but also seasoned pro.Unsafe Defaults
Kafka defaults tends to be optimized for the performance, and will need to be explicitly overridden on the client when safety is a critical objective. Remember the first rule of optimization: Don’t do it. Kafka would have been even better, had their creators given this more thought. Some of the specific examples I’m referring to are:enable.auto.commit
Default value for auto commit is set totrue, which results in consumers committing offsets
every 5 seconds (configured by auto.commit.interval.ms), irrespective of
whether the consumer has finished processing the record. We should set to this to false by
default, so that client application can dictate the commit point.
max.in.flight.requests.per.connection
Default value for max in-flight request per connection set to5, which may result in messages
being published out-of-order, if one (or more) of the enqueued messages times out and is retried. We should
set this to 1, so that we can maintain message ordering, only if business needs ordering.
Back-Pressure
Apache Kafka is capable of delivering messages over network as alarmingly fast rate, which can eventually causes a DoS attack, if we are using an unchecked Kafka Consumer. We can disable auto-commit by usingenable.auto.commit=false on consumer and commit only when consumer
operation is finished. That way consumer would be slow, but Kafka knows how many messages consumer
processed, also configuring poll interval with max.poll.interval.ms and messages to be consumed
in each poll with max.poll.records.
Format Conversion
We should avoid using older client with newer topic message formats, and vice versa, whenever possible as this adds additional load on the broker.Final Thoughts
Apache Kafka is a clear leader for stream data in real-time application development as it provides robust platform for enabling stream processing and enterprise communication. A broad range of event-driven application architectures can benefit having Kafka as the underlying messaging backbone.Apache Kafka Driblet

 CI/CD for the Unpredictable: Real-World LLMOps
CI/CD for the Unpredictable: Real-World LLMOps
Post a Comment
Post a Comment