Elasticsearch a
near real-time search engine, that means any changes to an index is propagated throughout the
Elasticsearch cluster within one second. This is somewhat similar to relational database
systems that are hosted on a single machine, where changes become instantly available. This slight delay is due
to Elasticsearch’s distributed architecture which makes the search engine so scalable. In fact,
for large clusters, a delay of one second is really impressive!

Source:
Image by storyset on Freepik
Field
Smallest individual unit of data in Elasticsearch. Each field has a defined datatype and contains a single piece of data.Those data types are:
Corestrings, numbers, dates, booleansComplexobject and nestedGeoget_point and geo_shapeSpecializedtoken count, join, rank feature, dense vector, flattened, etc.
Multi-fields
These fields can (and should) be indexed in more than one way to produce more search results. This option is available easily through themulti-fields option.
Meta-fields
Meta-fields deal with a document’s metadata.Analyzer
Allows us to convert unstructured text into a format optimized for search. Analyzers are used during indexing to break down – or parse – phrases and expressions into their constituent terms. Defined within an index, an analyzer consists of a single tokenizer and any number of token filters.Elasticsearch ships with a wide range of built-in analyzers, which can be used in any index without further configuration:
Standard Analyzer
Divides text into terms on word boundaries, as defined by the Unicode Text Segmentation algorithm. It removes most punctuation, lowercases terms, and supports removing stop words.Simple Analyzer
Divides text into terms whenever it encounters a character which is not a letter. It lowercases all terms.Whitespace Analyzer
Divides text into terms whenever it encounters any whitespace character. It does not lowercase terms.Stop Analyzer
Similar to the simple analyzer, but also supports removal of stop words.Keyword Analyzer
Accepts whatever text it is given and outputs the exact same text as a single term.Pattern Analyzer
Uses a regular expression to split the text into terms. It supports lower-casing and stop words.Document
Documents are JSON objects that are stored within an index and are considered the base unit of storage. In the world of relational databases, documents can be compared to a row in table. Documents also contain reserved fields that constitute the document metadata such as:_indexThe index where the document resides._idThe unique identifier for the document._sourceThe original JSON representing the body of the document.
Document Example
Mapping
Mapping is the process of defining how a document, and the fields it contains, are stored and indexed. Each document is a collection with their own data types.Mapping Example
Dynamic Mapping
Adds new fields mapping automatically, just by indexing a document. We can add fields to the top-level mapping, to inner object and nested fields. We should use dynamic templates to define custom mappings that are applied to dynamically added fields based on the matching condition.Explicit Mapping
Allows us to precisely choose how to define the mapping definition , such as:- Which string fields should be treated as full text fields.
- Which fields contain numbers, dates, or geolocations.
- The format of date values.
- Custom rules to control the mapping for dynamically added fields.
Index
An index is like a table in a relational database. It is a logical namespace (must be lowercased) which maps to one or more primary shards and can have zero or more replica shards. The names are used when indexing, searching, updating and deleting documents within indexes. We can define as many indexes as we want within a cluster depending on the scale of our project.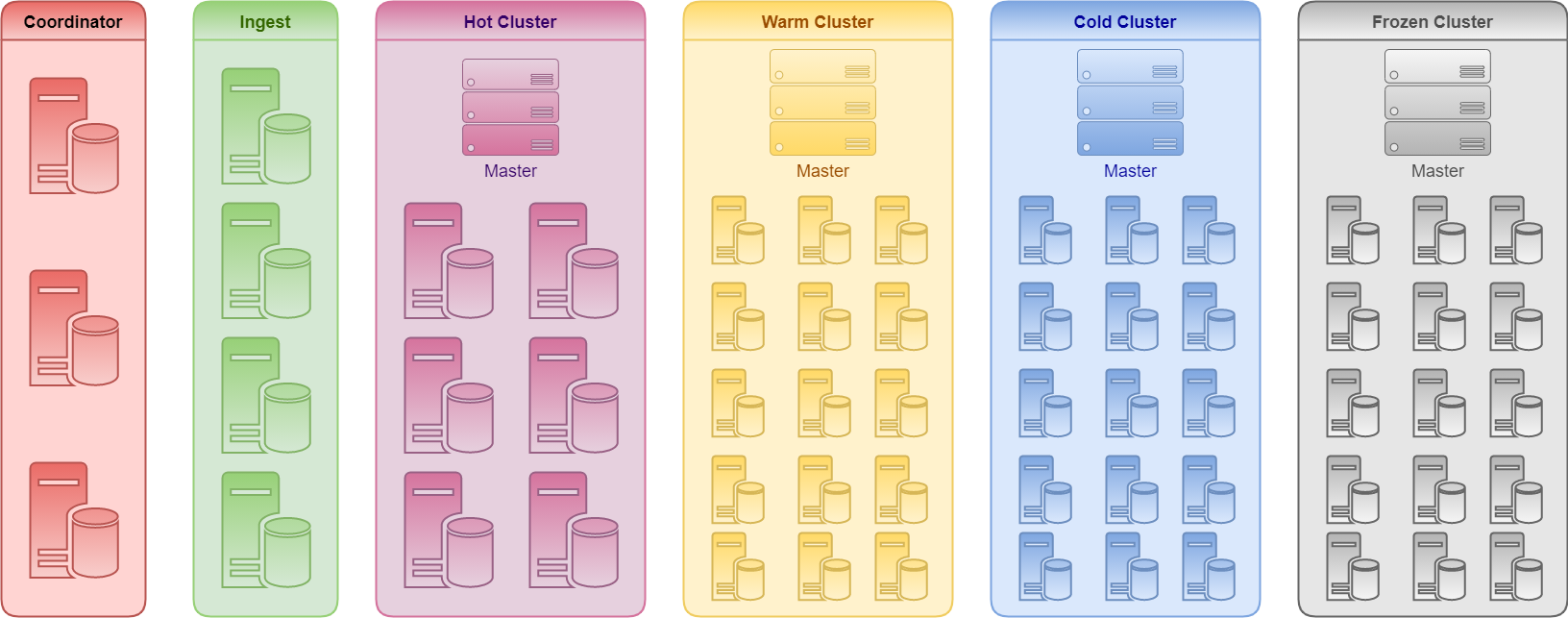 We can manage Index Lifecycle (ILM) using a lifecycle policy that specified following phases:
We can manage Index Lifecycle (ILM) using a lifecycle policy that specified following phases:
Hot
Handles all indexing of new data in the cluster and holds the most recent daily indices that tend to be queried most frequently. Indexing is an I/O intensive activity and the hardware these nodes run on needs to be more powerful and use SSD storage.Frequent Update, Frequent Queries, Searchable, Fast Response.
Warm
Handles a large amount of read-only indices that are not queried frequently. With read-only indices, warm nodes can use very large spindle drives instead of SSD storage. Reducing the overall cost of retaining data over time yet making it accessible for queries.No Update, Not Frequent Queries, Searchable, Fast Response.
Cold
Once data is no longer being updated, it can move from the warm tier to the cold tier where it stays while being queried infrequently. The cold tier is still a responsive query tier, but data in the cold tier is not normally updated. As data transitions into the cold tier it can be compressed and shrunken.No Update, Infrequent Queries, Searchable, Slow Response.
Frozen
Once data is no longer being queried, or being queried rarely, it may move from the cold tier to the frozen tier where it stays for the rest of its life.No Update, Rarely Queries, Searchable, Extremely Slow Response.
Delete
The index is no longer needed and can safely be removed.No Update, No Queries.
Node
A running instance of elastic search that stores data and participates in the cluster’s indexing and search capabilities. Just like a cluster, a node is identified by a name. We can define any name to a node in case we want to override default name. This name is important for administration purposes to identify which servers in network correspond to which nodes in the cluster. In a cluster, each node type has a different responsibilities:Master Node
A node that has the master role, which makes it eligible to be elected as the master node, which controls the cluster management and configuration actions such as adding and removing nodes.Data Node
A node that has the data role. Data nodes hold data and perform data related operations such as CRUD, search, and aggregations. A node with the data role can fill any of the specialised data node roles.Ingestion Node
A node that has the ingest role. Ingest nodes are able to apply an ingest pipeline to a document in order to transform and enrich the document before indexing. With a heavy ingest load, it makes sense to use dedicated ingest nodes and to mark the master and data nodes asnode.ingest: false.
Coordinating Only Nodes
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes.Adding too many coordinating only nodes to a cluster can increase the burden on the entire cluster.
Shards
An index can be divided into multiple pieces, and each piece is called a shard. This is useful if an index contains more data than the hardware of a node can store. A shard is a fully functional and independent index and can be stored on any node within a cluster. The number of shards can be specified when creating an index, but it defaults to five.The number of primary shards can not be changed after an index has been created
Shards Example
Replica
While shards improve the scalability of the content volume for indexes, replicas ensure high availability. A replica is a copy of a shard, which can take over in case a shard or a node fails. A replica never resides on the same node as the original shard, meaning that if the given node fails, the replica will be available on another node. Replicas also allow for scaling search volume, because replicas can handle search queries.In production application, all indices should have a replication factor of at least 1. Otherwise, we exposed to data loss if anything unexpected happens.
Cluster
A cluster is a collection of one or more nodes (or servers) with same name. A cluster can consist of as many nodes as we want, making it extremely scalable. The collection of nodes contain all of the data in the cluster, and the cluster provides indexing and search capability across all of the nodes. In practice, this means that when performing searches, we do not need to worry about which particular node a given document is stored on.Clusters are identified by a unique name, which defaults to elasticsearch.
Final Thought
These are the main concepts we should understand when getting started with Elastic Search, but there are other components and terms as well. We couldn’t cover them all, so I recommend referring to Elastic for additional information.
Happy searching and indexing!
Elasticsearch Driblet

 CI/CD for the Unpredictable: Real-World LLMOps
CI/CD for the Unpredictable: Real-World LLMOps
Post a Comment
Post a Comment