Cache is pronounced cash. It is a temporary memory to store the most
frequently accessed data that is originally stored elsewhere. The cache is used when the original/primary data source is
expensive to fetch data due to longer access time or to compute, compared to
the cost of reading the cache. Think of cache as a high-speed storage mechanism that can be either
reserved section of main memory or an independent high-speed storage device.

Caching should be done to decrease costs needed to increase performance and scalability and
NOTto solve performance and scalability problems of data sources.
Source: Designed by Freepik
In this blog, we will be discussing about backend side of things, which is vital to understand for
anyone working on or studying system performance and efficiency. Now the question is why backend caching
is important. The caching on the server side can significantly enhance application performance and efficiency of
an application by reducing load on the data source, cutting down latency, and
improving request handling capacity. It is like having a mini database that is
faster and quickly accessible.
Think about a cache as a place to store a subset of data - Typically, the most frequently used data - In a location where it can be accessed quickly.
Prerequisites
Before even deciding on the caching layer, you need to ask yourself the following questions:- Business - Which business use-case or requirement in your system requires high throughput, fast response, or low latency? What level of inconsistency is fine for the application?
- Data - What kind of data do you want to store or maintain? Objects, Static Data, Simple Key-Value Pairs, or Complex Data Structures? Are these transactional or master data sets?
-
Mode - Do you need an in-process or shared cache in a single node or distributed cache
for
N
number of nodes? If distributed, what about performance, reliability, scalability, and availability? - Invalidation - How cache should be invalidated? Will there be a general rule or does each object need some specific invalidation logic?
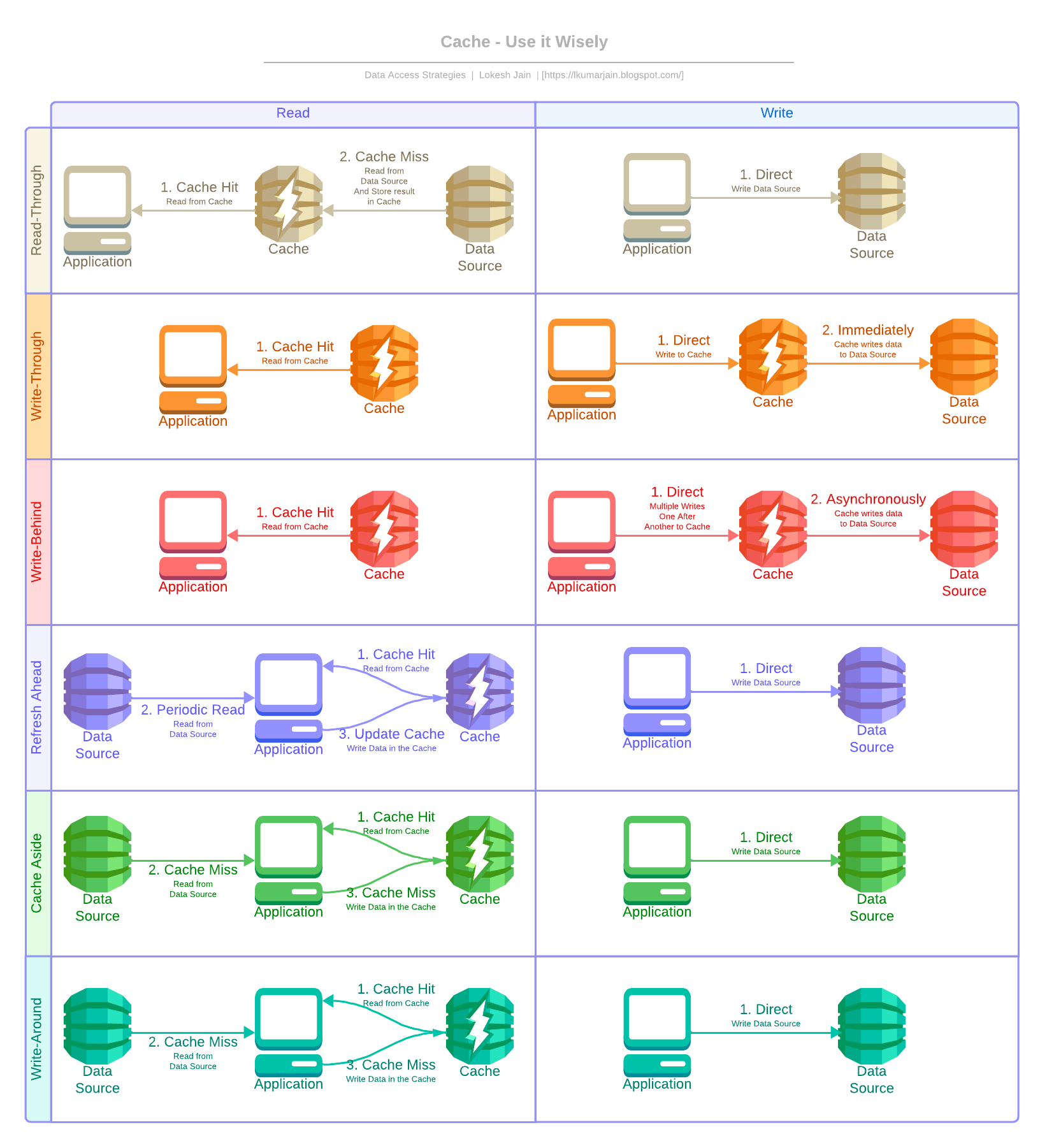
Data Access Strategies
System design depends a lot on the data access strategies, they dictate the relationship
between the data source and the caching system. So it is very important for us to choose the proper data
access strategy.
 Before choosing any strategy, you should analyze the access pattern of the data and try to
fit your application's suitability with any of the following:
Before choosing any strategy, you should analyze the access pattern of the data and try to
fit your application's suitability with any of the following:
Before choosing any strategy, you should analyze the access pattern of the data and try to
fit your application's suitability with any of the following:
Read Through / Lazy Loading
All the reads are directed to the cache, if the data is found in the cacheCache Hit, then return the data, otherwise Cache Miss fetch the data from the data
source, store it in the cache, and then return it. You can also
envision this as a read pipe between the application and data source with a cache in the
middle.
The Benefits
- On Demand by Nature - It does not load or hold all the data together, it's on demand by nature. Suitable only for the cases where application might not need to cache all data from data sources in a particular category.
- High Availability - It can failover on the another node in case of a node failure in the multi-node cluster. Which intern helps us to achieve high availability but latency can increase for the time being.
- Read Heavy - It works best for read-heavy workloads when the same data is requested many times.
The Trade-Offs
- Extra Penalty - When the data is requested the first time, it always results in cache miss and incur the extra penalty of loading data to the cache. Developers deal with this by warming or pre-heating the cache by issuing queries manually.
- Network Round Trips - For each cache miss, there are three network round trips. Check in the cache, retrieve from the data source, and put the data into the cache. So cache causes noticeable delay in the response.
- Stale Data - Stale data might become an issue. If data changes in the data source and the cache key is not expired yet, it will throw stale data to the application.
Write Through
All the writes are directed to the cache system which intern writes to the data source. Both of these operations should occur in a single transaction otherwise there will be data loss. This helps the cache maintain consistency with the main data source. You can also envision this as a write pipe between the application and data source to ensure that data is always consistent and up-to-date.The Benefits
- User Experience - The cache is ensured to have any written data and no new read will experience a delay while the cache requests it from the main data source.
- No Stale Data - It addresses the staleness issue of Read Through cache.
- Read Heavy Systems - Suitable for read-heavy systems which can't much tolerate staleness.
The Trade-Offs
- Write Penalty - Every write operation does two network operations — write data to cache, then write to the data source.
- Cache Churn - If most of the data is never read, the cache will unnecessarily host useless data. This can be controlled by using TTL or expiry.
- Operation Failure - To maintain the consistency between cache and data source, while writing data, if any of your cache nodes goes missing, the write operation fails altogether.
Write Behind / Write Back
All the write operations are directed to the cache. Then after a certain configured interval, the data will be written to the underlying data source asynchronously. So here the caching service has to maintain a queue of write operations, so that they can be synced in order of insertion. You can also envision this as a write pipe between the application and data source with delayed write to the data source.The Benefits
- Improves Performance - Since the application writes only to the caching service, it does not need to wait till data is written to the underlying data source. Read and write both happen on the caching side. Thus it improves performance.
- Insulated from Failure - The application is insulated from data source failure. If the data source fails, queued items can be retried or re-queued.
- High Throughput - Suitable for high read & write throughput system.
The Trade-Offs
- Eventual Consistency - Eventual consistency between data source and caching system. So any direct operation on data source or joining operation may result in stale data.
- Rollback Process - Since cache is written first and then data source — they are not written in a transaction, if cached items can not be written to the data source, some rollback process must be in place to maintain consistency over a time window.
- Data Loss - In case of a cache failure, this delay opens the door for possible data loss, if the batch or delayed write to the database has not yet occurred
Refresh Ahead
All the required data is loaded into the cache before first access. The data is refreshed before it gets expiredUsually a configured interval - usually less then expiry to serve latest data on the next
possible access although it might take some time due to network latency to refresh the data, meanwhile few
thousand read operation already might have happened in a very highly read-heavy system in just a duration of
few milliseconds.
The Benefits
- Periodic Refresh - It is useful when a large number of users are using the same cache keys. Since the data is refreshed periodically and frequently, staleness of data is not a permanent problem.
- Reduced Latency - Reduced latency than other techniques like Read Through cache.
The Trade-Offs
- Extra Pressure - Probably a little hard to implement since cache service takes extra pressure to refresh all the keys as and when they are accessed. But in a read-heavy environment, it's worth it.
Cache Aside
The cache is logically placed aside and the application directly communicates with the data source or the cache to know if the requested information is present or not. On a cache hit return data, whereas on a cache miss, retrieve data from the data source, return it, and then store it in the cache for future use.The Benefits
- Resilient - Systems using cache-aside are resilient to cache failures. If the cache cluster goes down, the system can still operate by going directly to the data source.
The Trade-Offs
- Spikes Handling - Provides Full control over cache access and cache update logic but it isn't a long-term or dependable solution for peak load or spikes that can happen suddenly.
- Inconsistency - Any data being written will go directly to the data source. Therefore, the cache may have a period of inconsistency with the primary data source.
Write Around
All the write operations bypass the cache and directly write into the data source. The data does not reflect on the cache immediately. This is most performant in instances where data is only written once. If there is a cache miss, then the application will read to the data source and then update the cache for next time.Eviction / Invalidation Policy
Cache eviction policies determine how long data remains in the cache before being
removed or refreshed. The policy is important to ensure that the cache
remains efficient and does not become a bottleneck in the system. Poorly chosen policies can result in
increased cache misses and reduced system performance. As a result, careful consideration should be given
to appropriate policy selection and monitoring its performance over time. The common eviction policies are:
Time-Based
The data is removed or refreshed from/in the cache after a fixed amount of time - TTL. This is useful for data that is not frequently accessed and does not need to be kept in the cache for long periods.Event-Based
The data is removed or refreshed from/in the cache when a specific event is triggered in the system. This type of invalidation is useful when the cached data is associated with a specific event or state change and must be updated properly.Size-Based
The data is removed from the cache based on the size of the cache. When the cache reaches a predetermined size, data is removed using the following techniques to make room for new data when cache reaches its maximum capacity.- First In, First Out (FIFO) - The oldest items are removed first.
- Last In, First Out (LIFO) - The most recently added items are removed first.
- Least Recently Used (LRU) - The data that has not been accessed for the longest time is removed first.
- Most Recently Used (MRU) - The most recently accessed items are removed first.
- Least Frequently Used (LFU) - The data that has been accessed the least number of times is removed first.
- Random Replacement (RR) - The data is randomly removed.
Data Type Wise
Different caching technology/frameworks serves well to different data types due to their internal architecture/design. So choosing the correct technology/frameworks, also depends on what type of data they can efficiently store. Some of them are:- Object Store - Suitable to store immutable/unmodifiable objects like HTTP Response Objects, Database Result Sets, Rendered HTML Pages, etc, then Memcached, Redis, and In-Memory Caching Frameworks. with benchmarks are a good choice.
- Key-Value Store - Storing a simple string key to a string value is almost supported by any cache.
- Native - If your use case supports storing in and retrieving data from natively supported data structures, then Redis, and Aerospike are good choice.
- In-Memory - Suitable to store any key-value or objects directly accessible through run time memory in the same node, then In-Memory Caching Frameworks. with benchmarks is a good choice.
- Static File - Suitable to cache images, files, and static files like — CSS or javascript files, then Akamai CDN, Cloudfront, and Memcached to a certain extent are good choice.
Caching Mode
Caching is essential in the pursuit of enhancing application performance. In this section,
we will venture into the realm of diverse caching techniques, encompassing In-Memory, Distributed, and
Persistent caching.
In-Memory / In-Process Cache
This is a caching mode for non-distributed (standalone) systems, the applications instantiate and manage their own or 3rd party cache objects. Both application and cache are in the same memory space. Reading data from process memory is extremely fast (sub-millisecond) as a result This significantly faster data access improves the overall performanceenhanced user experience and responsiveness of the application.
- Popular Frameworks - Some popular Golang In-Memory Caching Frameworks. with benchmarks.
- Advantages - Locally available data, so highest speed, easy to maintain.
- Disadvantages - High memory consumption in a single node, cache shares memory with the application. If multiple application relies on the same set of data, then there might be a problem of data duplication.
- Use Case - This type of cache is used for caching database entities but can also be used as some kind of an object pool, for instance pooling most recently used network connections to be reused at a later point.
Distributed Cache
Distributed cache is a data caching mechanism that spans across multiple networked servers or nodes. A Distributed cache divides the cache into segments and distributes them such that each node in a cluster of servers contains only one segment of the entire cache. In this way, the cache can continue to scale by simply adding new nodes to the cluster.- Popular Frameworks - Some popular distributed caching frameworks are Redis, Memcached, Aerospike, Hazelcast and Ehcache
- Advantages - It enhances scalability, fault tolerance, and data retrieval speed by distributing and locally serving cached data across nodes.
- Disadvantages - Every cache request results in a round trip to a Node regardless of cache hit or miss.
- Use Case - When we talk about internet-scale web applications, or microservices, we actually, talk about millions of requests per minute, petabytes, or terabytes of data in the context. So a single dedicated powerful machine or two will not be able to handle such a humongous scale. We need several machines to handle such scenarios. Multiple machines from tens to hundreds make a cluster and at a very high scale, we may need multiple such clusters.
- Key Requirements - An effective distributed caching solution should support Elastic scalability.
Persistent Cache
Persistent cache stores frequently accessed or critical data on disk drives to offer a balance between performance and data persistence. It enables applications to retrieve data more rapidly than fetching it from external sources, enhancing efficiency while maintaining data durability.- Popular Frameworks - Some popular Persistent caching frameworks are Redis and Ehcache
- Advantages - Provides larger storage capacity than RAM.
- Disadvantages - In distributed systems with data replication, stale data can occur when updates are made to the data on one replica but not propagated to other replicas. As a result, different replicas may have inconsistent or outdated versions of the data.
- Use Case - This cache is commonly used in applications that require persistent cache, such as video streaming applications.
Benefits and Limitations
Cache brings significant benefits in terms of enhanced performance and improved user experience, but as we all know nothing comes for free, cache comes up with its own tradeoffs and considerations. It is important to balance its remarkable benefits and the potential complexities and challenges it may introduce.The Significant Benefits
- Reduces Data Retrieval Time - Caching keeps frequently accessed information ready to use, which makes getting data faster than pulling it fresh from the Services.
- Lowers Server Load - By storing data temporarily closer to the caller, it reduces the amount of work services have to do, helping them run smoother.
- Saves Network Bandwidth - It cuts down on the amount of data that travels across the network, which can help avoid clogging up internet connections.
- Improves User Experience - When websites and apps load quickly and run smoothly, people using them tend to have a better time and feel less frustration.
- Decreases Latency - Caching shortens the delay between a user's action and the response from the service, making everything feel more instant and responsive.
The Main Trade-Offs
- Increased Design Complexity - Caching adds more layers to a system's architecture, making it harder to build and understand.
- The Risk of Outdated Content or Stale Data - Sometimes, cached data doesn't get updated when the original data changes. This means users might see old information that is no longer correct or relevant.
- Uses Additional Memory Resources - To store cached data, a system needs extra memory. This can be costly and take away resources from other parts of the system that might need them.
- Potential for Data Security Issues - Cache can lead to risks if sensitive information is not protected properly. If a breach occurs, this could expose private data to unauthorized people.
- Maintenance and Consistency Challenges - It can be tough need extra work to make sure that the cached data is the same as the data in the main storage.
Final Thought
Caching is a powerful optimization technique that can significantly improve system performance and reduce latency. You should make an informed decisions by considering the data being cached, data access strategy, and eviction policies and monitor the cache's hit v/s miss ratio, latency and data eviction rate to ensure cache performance.
Caching is the tradeoff between Performance and Freshness!
Cache Driblet

 CI/CD for the Unpredictable: Real-World LLMOps
CI/CD for the Unpredictable: Real-World LLMOps
Post a Comment
Post a Comment